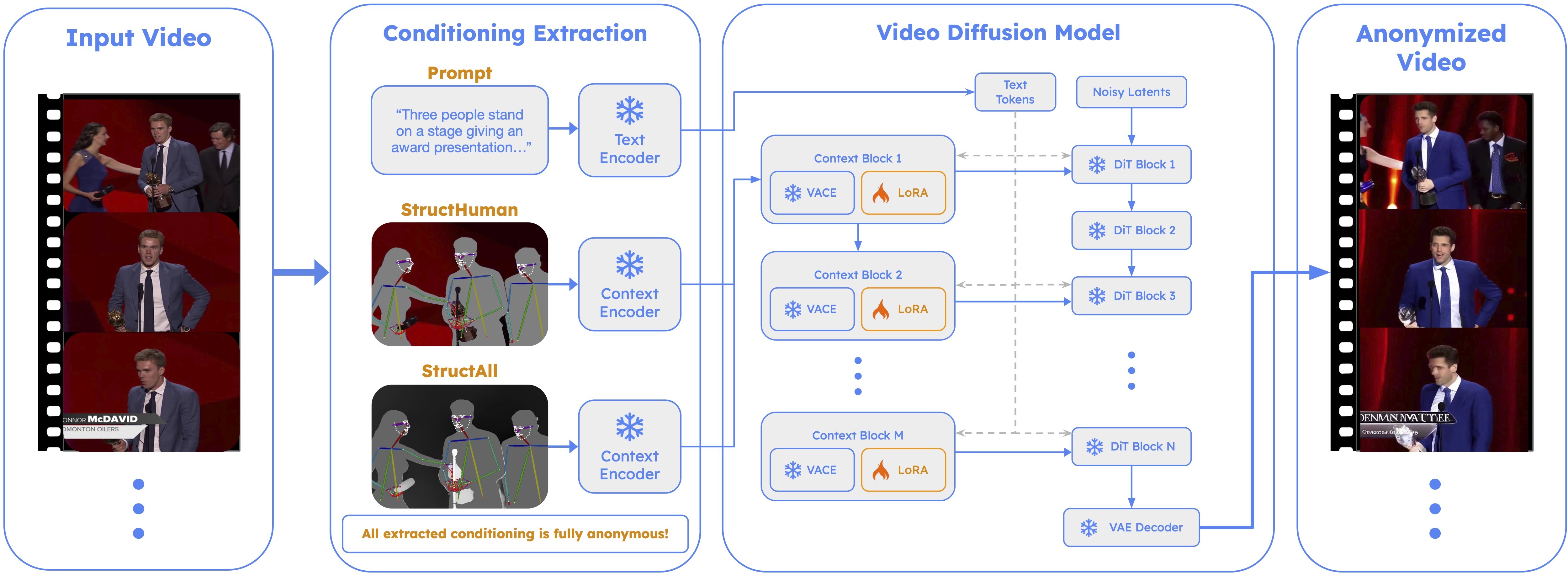
Human-centric video is everywhere—and almost always identifiable. To share or train on
it safely, we need to anonymize the people in it. However,
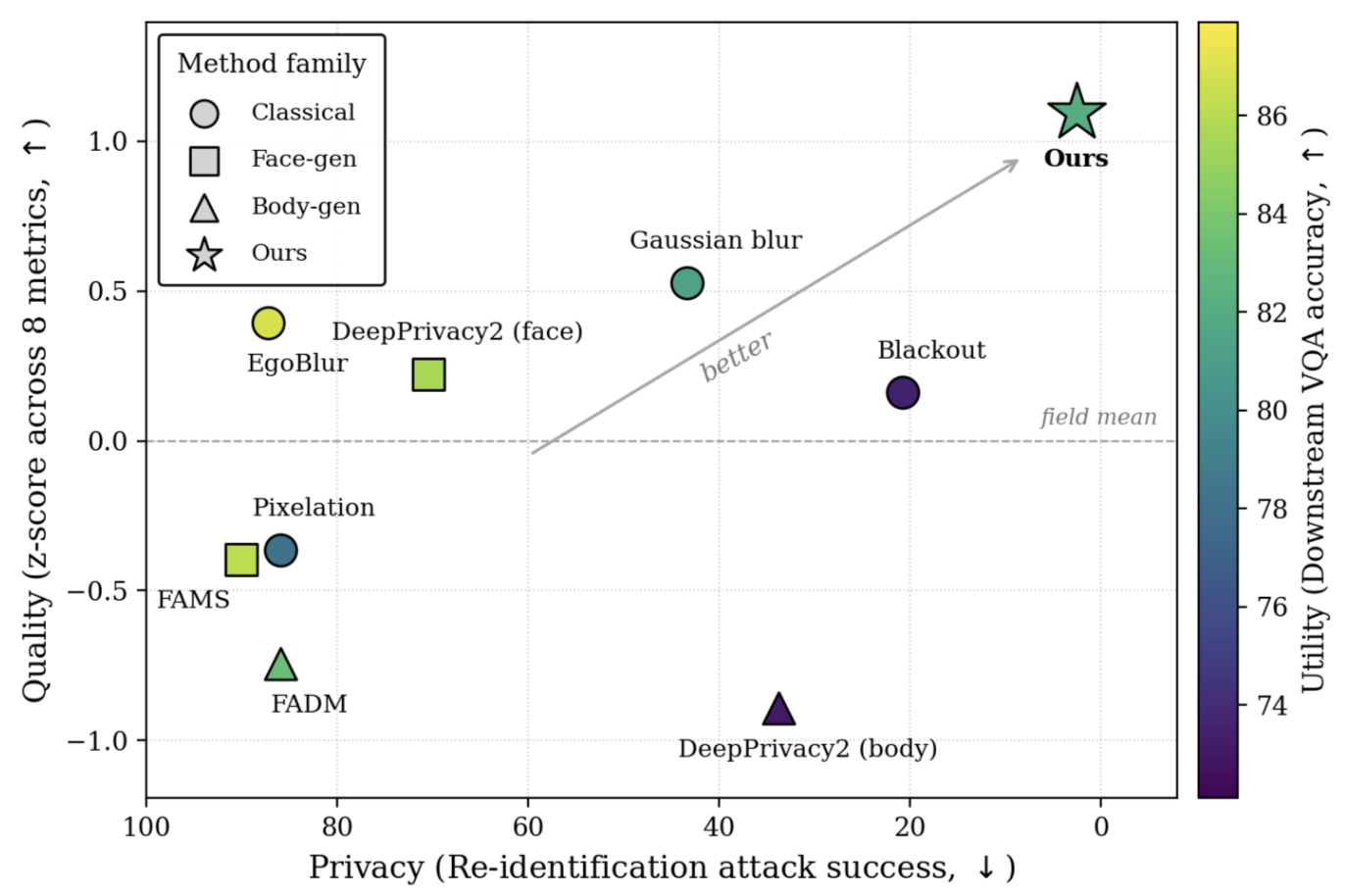
blurring and redacting detected humans destroys realism and negatively effects
downstream usability, while existing generative anonymization methods generate frame-by-frame, resulting in temporal flickering and identity drift.
Our insight is simple: regenerate, don't edit. Instead of hiding or editing the original video directly (which compromises privacy), we throw their pixels away entirely and regenerate the human pixels from
identity-free structural cues—pose, depth, and segmentation—using a video diffusion
model that denoises the whole clip at once. Because no original human pixel ever reaches the
output, privacy is guaranteed by construction, and because the clip is generated jointly,
the result is temporally consistent.